Scaling graphql subscriptions at Slite
This article was originally posted by myself on Slite’s blog but it isn’t reachable anymore. It was featured on the GraphQL Weekly newsletter and I wanted to keep it available for everyone. Slite kindly allowed me to re-publish it here.
Preamble
We at Slite use a lot of GraphQL, which is a superb technology. But as for all technologies, you can end up shooting yourself in the foot. Today, we would like to explain how we designed our first real-time GraphQL implementation, how it ended up DDOS-ing ourselves, and then explain how we fixed it.
This article assumes you already have some knowledge of GraphQL and the types of operations it supports. You can read more about it in details on the official website, but if opening a new tab takes too much energy, or your browser already looks like this

we tried boiling down the important concepts you should know about for this article in this preamble.
This is by no means an exhaustive explanation of those operations, feel free to go through the official documentation to learn more.
Query
A query is similar to a GET REST operation. It is how you retrieve data from a GraphQL API and it is expressed as follows:
query {
# Get the currently authenticated user
viewer {
# Select the fields we want for the authenticated user.
id
displayName
}
}Mutation
These are the kind of operations you would use to make changes on your API. Anything producing a change would usually be a mutation
mutation {
updateMyDisplayName(newDisplayName: "Foobar")
}Subscription
The most important kind of operation for this article.
A subscription is akin to a query as it will allow you to retrieve data from the GraphQL API.
It may help to think of mutations as a webhook, with which API users can subscribe to a specific query in order to receive data as soon as it becomes available.
By default subscriptions are transmitted by websockets but the transport layer is not exactly part of the GraphQL system in itself.
The transport layer is interchangeable and could, for example, be switched so that subscriptions results are sent as HTTP calls to a pre-defined endpoint, thus behaving exactly like a classic webhook.
Our usage at Slite
At Slite we build an app for collaborative remote work. Our editor is real-time and our goal is to make working on a document with your coworkers a delight 🥰
We wanted to offer the same kind of experience for everything related to the UI and all that it implies. However, polling techniques aren’t great for backend pressure and we were already using GraphQL for our API so we decided to use GraphQL subscriptions (over websockets) as well even though the technology was still a bit young at the time.
Whenever a person loads the app, we immediately set up a websocket connection to our subscriptions API and make the necessary subscription queries (called operations) to subscribe to the changes we deem necessary (some are global, some are only established in certain conditions/contexts) to update our users’ UI in real-time.
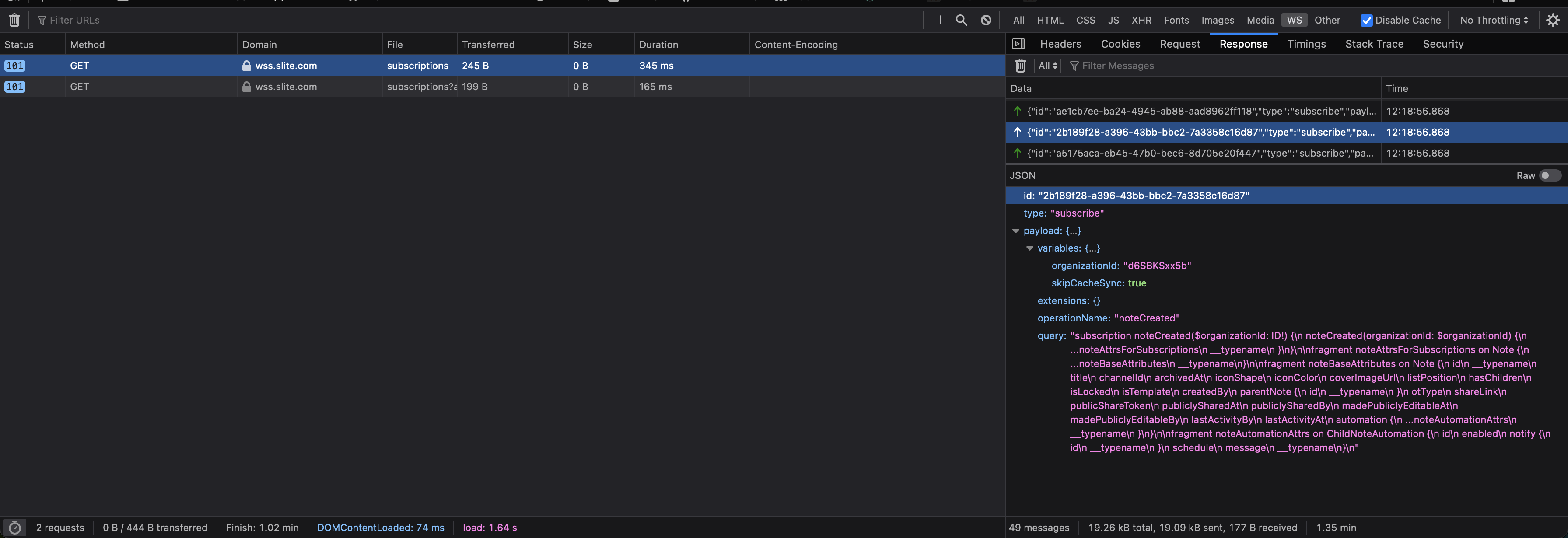
The first implementation
Our first implementation was quite naive, but helped us get started and worked very well for for nearly 2 years.
If you look at the suggested implementation (in packages like, now deprecated, subscriptions-transport-ws or graphql-ws), you’ll see it is quite straightforward to use and it basically:
- Sets up a websocket server
- Handles websocket communication protocol for you
- Handles GraphQL operations establishment
- Subscribes to a PubSub for incoming messages
- Performs GraphQL subscriptions execution
- Sends execution results to the connected clients.
For the most visual bunch of you 👀 , this is the implementation:
While this is great to start playing with, it doesn’t scale very well if your API is somehow I/O bound for its subscriptions execution (in our case, mostly database lookups)
In classic real-time systems (think rest-like webhooks) the servers publishing the messages to be relayed to clients would pre-compute the entire message and would push that payload to the PubSub channel for the clients to be updated. This is great for simple usages, however if you want to have user-tailored messages it introduces quite some complexity in the publisher as it will have to deal with personalized computations before sending them.
GraphQL, with its field-based resolution system, allows us to publish very generic messages while the subscription system computes the personalized message for every subscriber directly. This makes for a much simpler system to reason about.
Sadly, it also means that resolving subscription payloads requires the subscription system to have access to the databases and being able to execute queries to retrieve the required information, and when your number of clients grows you start having a problem.
The problem
Let’s assume we have a team of 1,000 users, subscribed to a generic onDocumentCreated subscription that has a user-specific permissions field.
type Document {
id: ID!
# This is user based, meaning each user will have values tailored
# to their roles / however you represent that in your system.
permissions: UserPermissions!
}
type Subscription {
onDocumentCreated: Document!
}If our API dispatches a documentCreated payload, our subscriptions system will have to resolve the permissions field for each connected user, leading us into the n+1 problem
Ideally we would use a DataLoader to deal with this issue, but because of how subscriptions are architectured, we are not able to do this as each connected user would have its own GraphQL context, therefore not sharing dataloaders.
Effectively, this means this event (remember, documentCreated for 1,000 users) would try to query for permissions for 1,000 different users, resulting in 1,000 SQL queries being made in the same short window.
Now, because of scaling and performance reasons SQL servers (in our case, PostgreSQL) usually wouldn’t allow you to establish an infinite amount of connections to the server so it means handling such a subscription would instantly deplete our SQL connections pool and we would have operations piling up waiting for connections to become available.
Because NodeJS is an event-loop based system, tasks in the event loop would start accumulating whilst waiting for SQL connections to become available. In turn, this would make node’s garbage collector go crazy trying to remove objects from the memory old space effectively slowing down the event loop altogether, and therefore all the incoming real-time messages would be waiting in line to be executed, making our real-time system not-so-real-time anymore 😔
While investigating we found that when receiving messages lots of users were interested in, we would have the following sequence:
- GraphQL resolvers execution would start piling up, waiting for SQL connections to become available.
- Garbage Collector would go crazy, having to scan through more and more objects each time it ran
- As a result, the Event loop lag would start increasing
- Memory usage would start increasing as the garbage collector didn’t have anything to clean
- Until the process would get killed because of Out of Memory errors (usually)
As a result we observed:
- Increasingly slower delays in propagating real-time events
- Missed real-time events (whenever the process would get killed we would lose the pending executions)
This can be seen in the following graphs obtained during our investigation of the issue
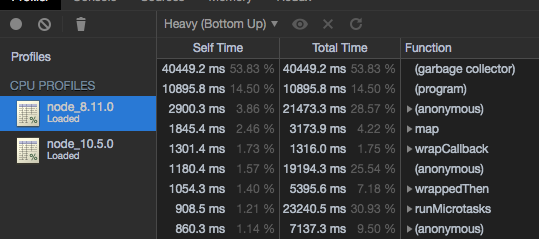
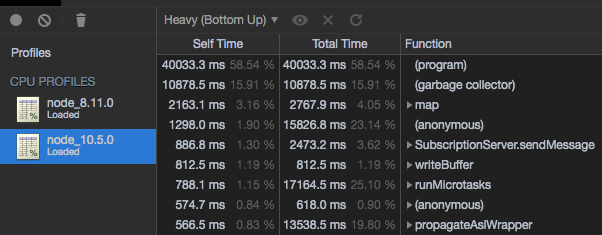
We initially diagnosed this issue as a memory leak one, and node 10 brought lots of improvements on the garbage collection process, so this was a before/after benchmark of that situation.
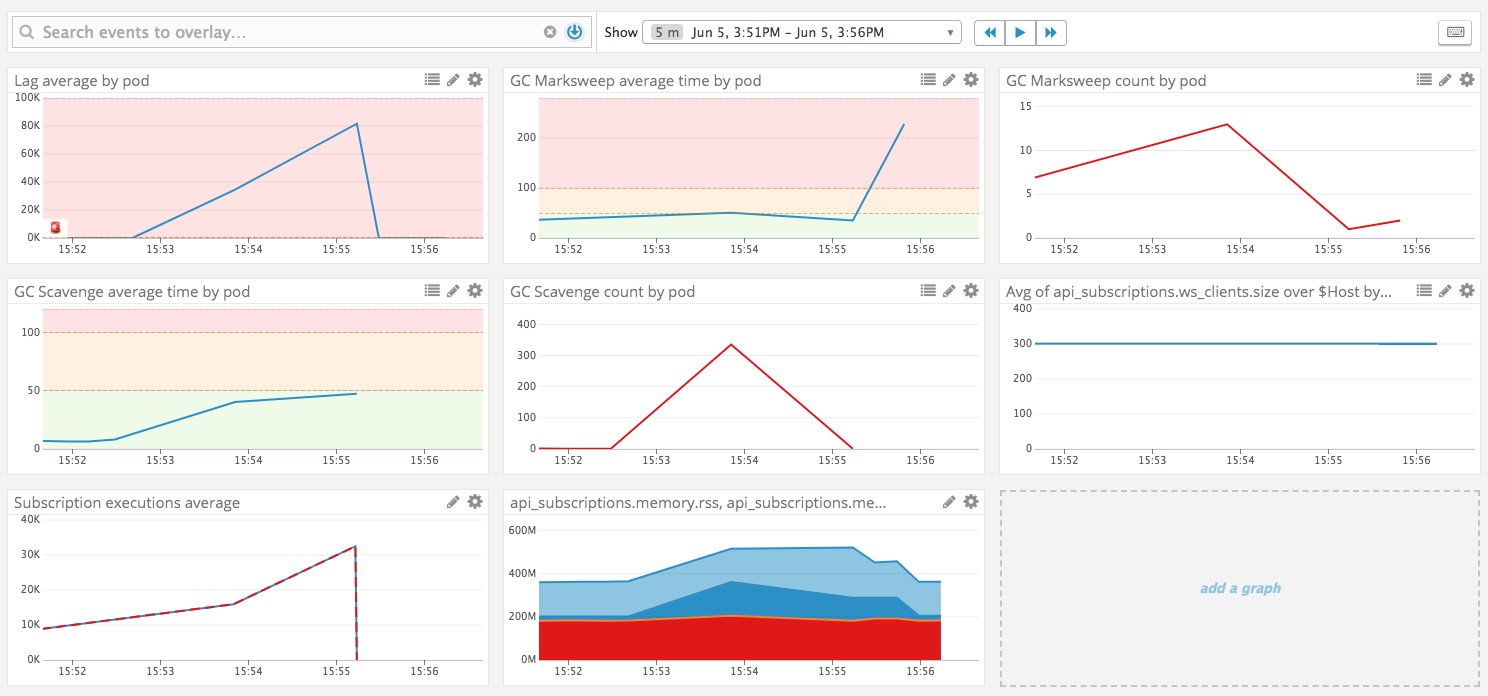
_As explained above, you can see all the health metrics going up, event loop lag, Garbage collection times, Memory usage. As soon as we stop hitting the server with messages everything goes back down. _
In effect, what we were seeing at the time was just us doing a Denial of Service attack on ourselves, which let’s be honest, is not the best thing to realize 😅
Since we noticed the process would go back to normal whenever we would stop stressing it, we finally realized it wasn’t about a memory leak (even though it really looked like it was), and we were onto something.
Our solution
The problem at our hands was basically that both resolution and dispatch were happening in the same process. Because we weren’t able to share context between the resolutions, this didn’t scale at all and we were hitting the limits of the naïve implementation.
Our goal with the change was:
- Having better control of volumes and remove the delay in operation resolutions
- Removing the websocket-load link so we could scale the number of websockets connections without it impacting our process load.
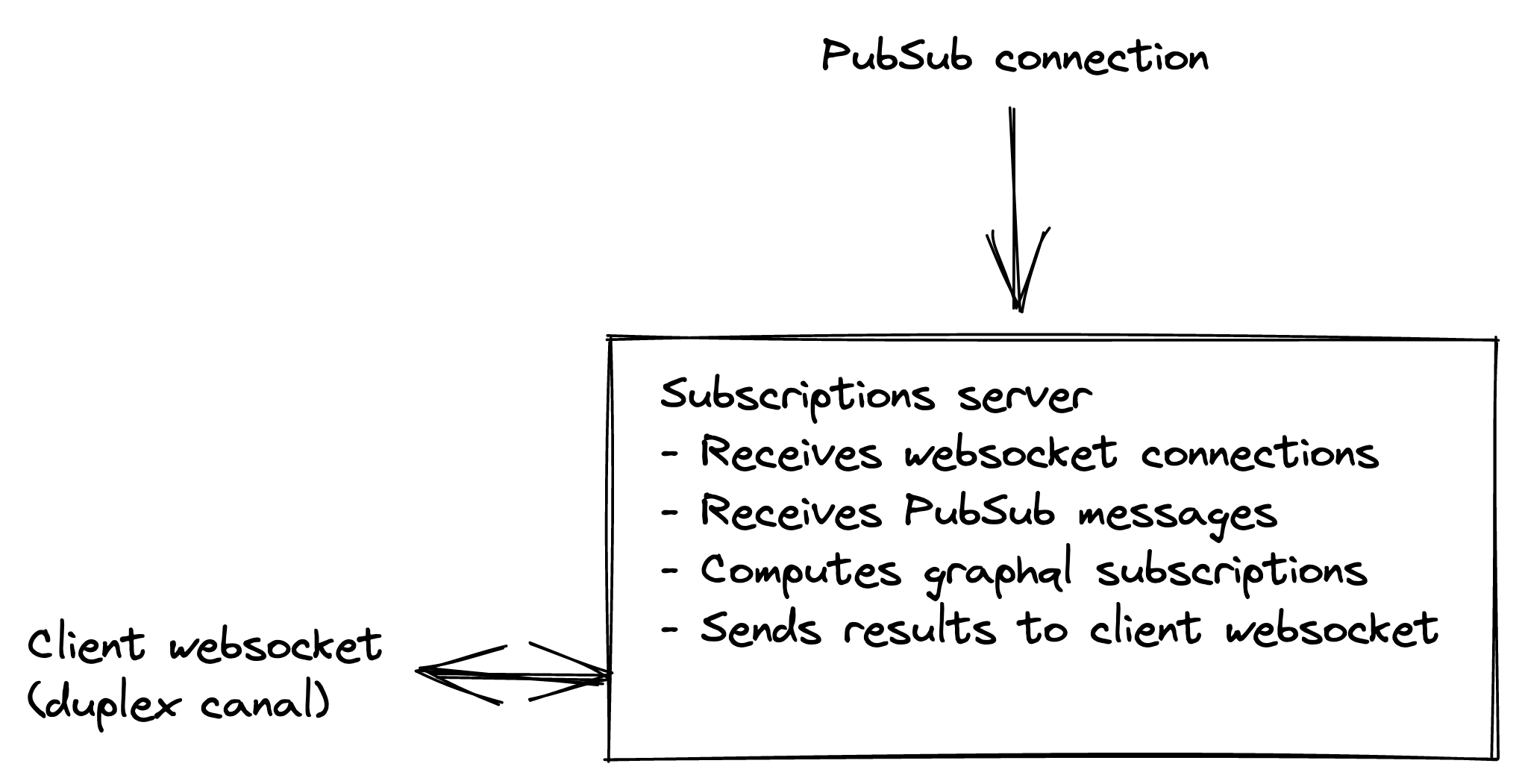
So in essence the new system we designed is the following:
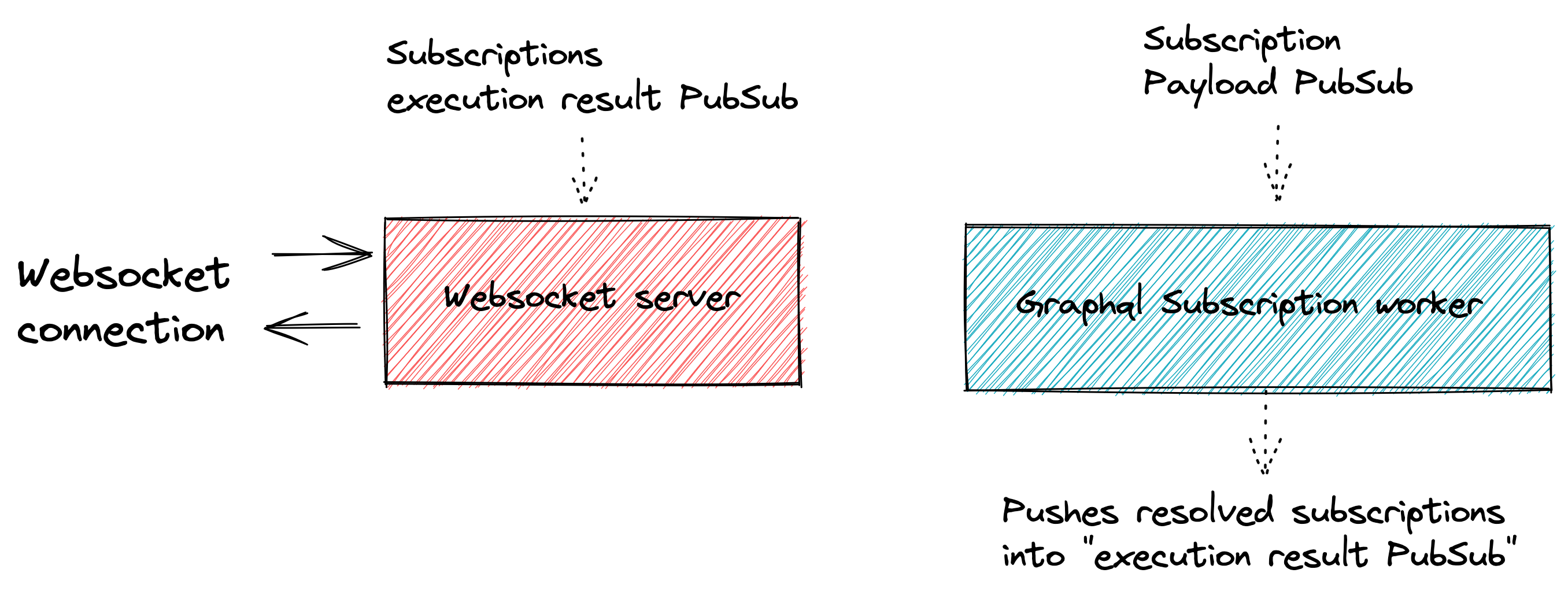
Websocket Server
This new service is responsible for:
- Validating websocket connections (we use JWT tokens, so it just knows how to verify these tokens’ signature)
- Maintaining websocket connections
- Validating graphql subscription operations
- Storing valid operations in a Redis specific storage
- Receiving subscription execution results and sending them to the websocket they belong to
Since we greatly reduced the responsibilities of this service, it is easier to scale (we’re not limited by SQL connections anymore) and we can just spawn these fast when our load grows during the day.
GraphQL Subscription Worker
We introduced this new server in order to have an easier control over the GraphQL execution process. Since we know most messages will interest several connected clients, we introduced a shared context for messages computations which allows us to use DataLoaders and have much better performances and smarter SQL usage whilst computing messages.
Instead of computing each websocket-message separately, we now compute the messages for all interested websockets at once, effectively improving our resolution times and data sharing.
In essence this service is:
- An internal service only and no one directly connects to it.
- Subscribing to a PubSub to which other process can send our real-time payloads
- Finding clients interested in receiving the result of the real-time payload computation
- Compute real-time payloads for all
Ninterested clients in the most optimal way possible - Send results of those computations to the
execution result PubSubfor theWebsocket Serverto handle those and propagate the results to our clients.
The situation today
This has allowed us to have a much better control over our real-time system and to scale in a much comfortable fashion. We wanted peace of mind, and as you will see, this delivered quite well.
Sadly we don’t have metrics to show the before/after on an exact same situation. You can compare some of these with the graphs shared in the “The Problem” section to have some kind of idea around it.

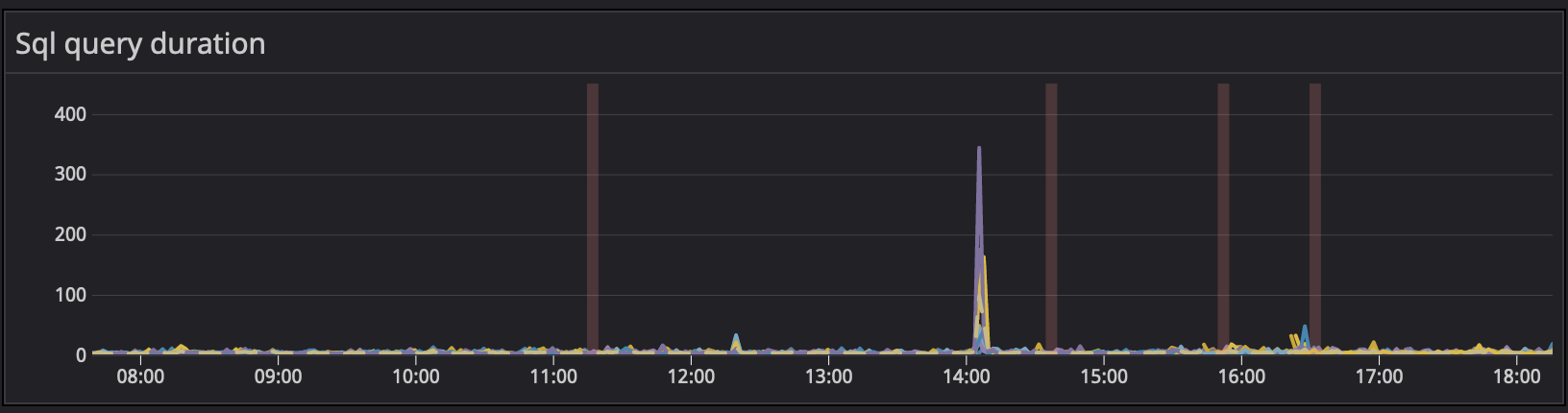

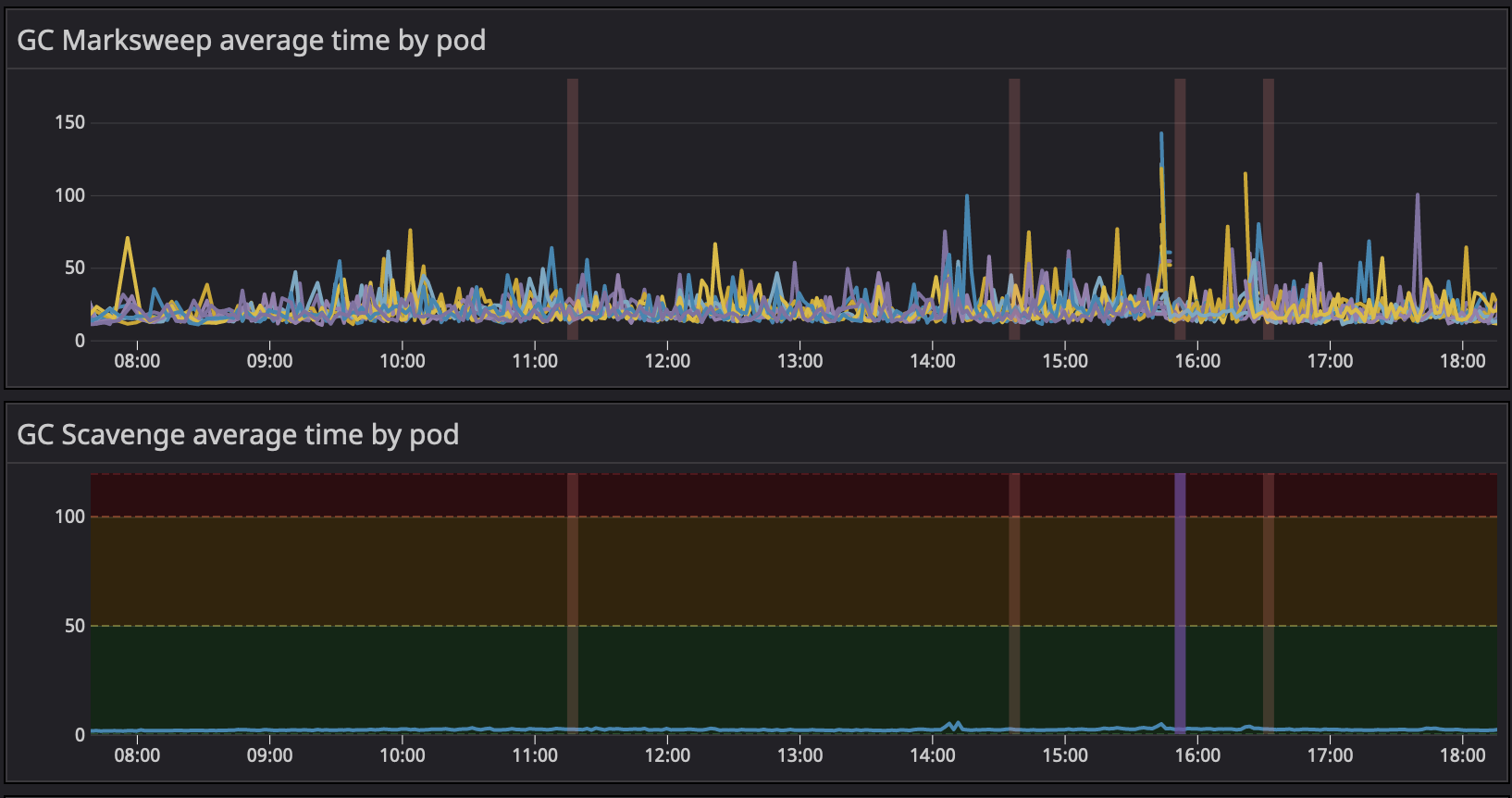
Conclusion
Whilst the base implementation given by the community solutions is great to start with, it doesn’t always scale and you will need to go beyond the out-of-the-box solution sometimes. Don’t be afraid to explore, stay hungry, stay foolish.
GraphQL subscriptions are still a “new” topic and it’s still evolving so we’re pretty sure great stuff will be coming in the future around it.
With this architecture, we freed ourselves (for now) of the scaling problem and it’s been smooth sailing ⛵ so far.
This solution sparks joy ✨, so we kept it and we figured you’d be interested in knowing more about how to scale such a system in a production environment.
We hope you liked this article,
Cheers 👋